

Examples#
We are going to use two examples to illustrate how to use Kulprit.
In the body fat example the aim of the analysis is to predict an expensive and cumbersome water immersion measurement of body fat percentage (observed variable named
siri) from a set of thirteen easier to measure characteristics, includingage,height,weight, and circumferences of various body parts [5]. Can we reduce the number of predictors while maintaining predictive accuracy?In the bikes example we have a dataset containing the number of bike rentals per hour (
count) in a bike-sharing system, along with several features that can be used to predict the number of rentals, includingtemperature,windspeed,hour, among others. Do we need all these predictors to make accurate predictions?
from arviz_plots import style
import bambi as bmb
import kulprit as kpt
import numpy as np
import pandas as pd
style.use("arviz-variat")
SEED = 9352
np.random.seed(SEED)
Body Fat#
The first thing we need to do is to load the data and define a model using Bambi. We are going to use a linear regression with Normal response. We need to compute the log_likelihood (model.compute_log_likelihood(idata)) as we will later need to compute the ELPD of the reference models and submodels.
body = pd.read_csv("body_fat.csv")
model = bmb.Model("siri ~" + " + ".join([c for c in body.columns if c!="siri"]), data=body)
idata = model.fit(random_seed=SEED)
model.compute_log_likelihood(idata)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [sigma, Intercept, age, weight, height, neck, chest, abdomen, hip, thigh, knee, ankle, biceps, forearm, wrist]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 16 seconds.
Before doing the projection and variable selection, it is a good idea to check that the reference model fits well the data and that MCMC sampling diagnostics are ok. In this example we will skip this step for brevity, but in a real analysis you should not. It makes little sense to perform variable selection using a model that we don’t trust!
Performing the projection#
To use Kulprit we first instantiate the ProjectionPredictive class and then call the project method, which is the one doing all the hard work.
ppi = kpt.ProjectionPredictive(model, idata)
ppi.project()
Inspecting the results#
Once this is finished we can print the ppi object. It will give us a list of the submodels in order of lowest ELPD to highest ELPD. The first model is always the intercept-only model, represented as an empty list.
ppi
0 []
1 ['abdomen']
2 ['abdomen', 'weight']
3 ['abdomen', 'weight', 'wrist']
4 ['abdomen', 'weight', 'wrist', 'height']
5 ['abdomen', 'weight', 'wrist', 'height', 'age']
6 ['abdomen', 'weight', 'wrist', 'height', 'age', 'chest']
7 ['abdomen', 'weight', 'wrist', 'height', 'age', 'chest', 'forearm']
8 ['abdomen', 'weight', 'wrist', 'height', 'age', 'chest', 'forearm', 'neck']
9 ['abdomen', 'weight', 'wrist', 'height', 'age', 'chest', 'forearm', 'neck', 'biceps']
10 ['abdomen', 'weight', 'wrist', 'height', 'age', 'chest', 'forearm', 'neck', 'biceps', 'ankle']
11 ['abdomen', 'weight', 'wrist', 'height', 'age', 'chest', 'forearm', 'neck', 'biceps', 'ankle', 'hip']
12 ['abdomen', 'weight', 'wrist', 'height', 'age', 'chest', 'forearm', 'neck', 'biceps', 'ankle', 'hip', 'knee']
13 ['abdomen', 'weight', 'wrist', 'height', 'age', 'chest', 'forearm', 'neck', 'biceps', 'ankle', 'hip', 'knee', 'thigh']
The ELPD is a measure of how well the model predicts the data, the higher the ELPD, the better the model. The ELPD is computed using the PSIS-LOO-CV method, which is an efficient way to approximate leave-one-out cross-validation [3, 4].
Using the method compare we can get a DataFrame ELPD of the reference model and all the submodels. The DataFrame also includes the standard error of the ELPD. The reference model is always on the first row, followed by the submodels in order of increasing ELPD.
In the following code block we are asking for all the submodels with minimum size of 1, that is, we are excluding the intercept-only model. We are also showing the transposed DataFrame with values rounded to 2 decimal places for better readability.
cmp_df = ppi.compare(min_model_size=1, round_to=2)
cmp_df.T
| reference | thigh | knee | hip | ankle | biceps | neck | forearm | chest | age | height | wrist | weight | abdomen | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| elpd | -726.96 | -723.73 | -724.03 | -723.03 | -722.64 | -721.85 | -722.31 | -723.01 | -723.43 | -724.51 | -725.09 | -725.77 | -730.19 | -747.84 |
| se | 9.41 | 8.91 | 8.67 | 8.70 | 8.68 | 8.67 | 8.72 | 8.63 | 8.54 | 8.67 | 8.54 | 8.52 | 8.62 | 8.92 |
| elpd_diff | 0.00 | 3.23 | 2.93 | 3.93 | 4.32 | 5.11 | 4.65 | 3.94 | 3.53 | 2.45 | 1.86 | 1.19 | -3.24 | -20.88 |
| dse | 0.00 | 0.64 | 1.39 | 1.44 | 1.56 | 1.75 | 2.03 | 2.49 | 2.74 | 3.00 | 3.43 | 3.56 | 4.91 | 6.70 |
Reading a table/DataFrame can be hard, So we usually recommend instead to focus on visually checking the results using the plot_compare function. This function represents the reference model’s ELPD as a horizontal line, with a band representing the uncertainty of the estimate. The submodels are represented as points, with a vertical line representing the uncertainty of the estimate.
kpt.plot_compare(cmp_df);
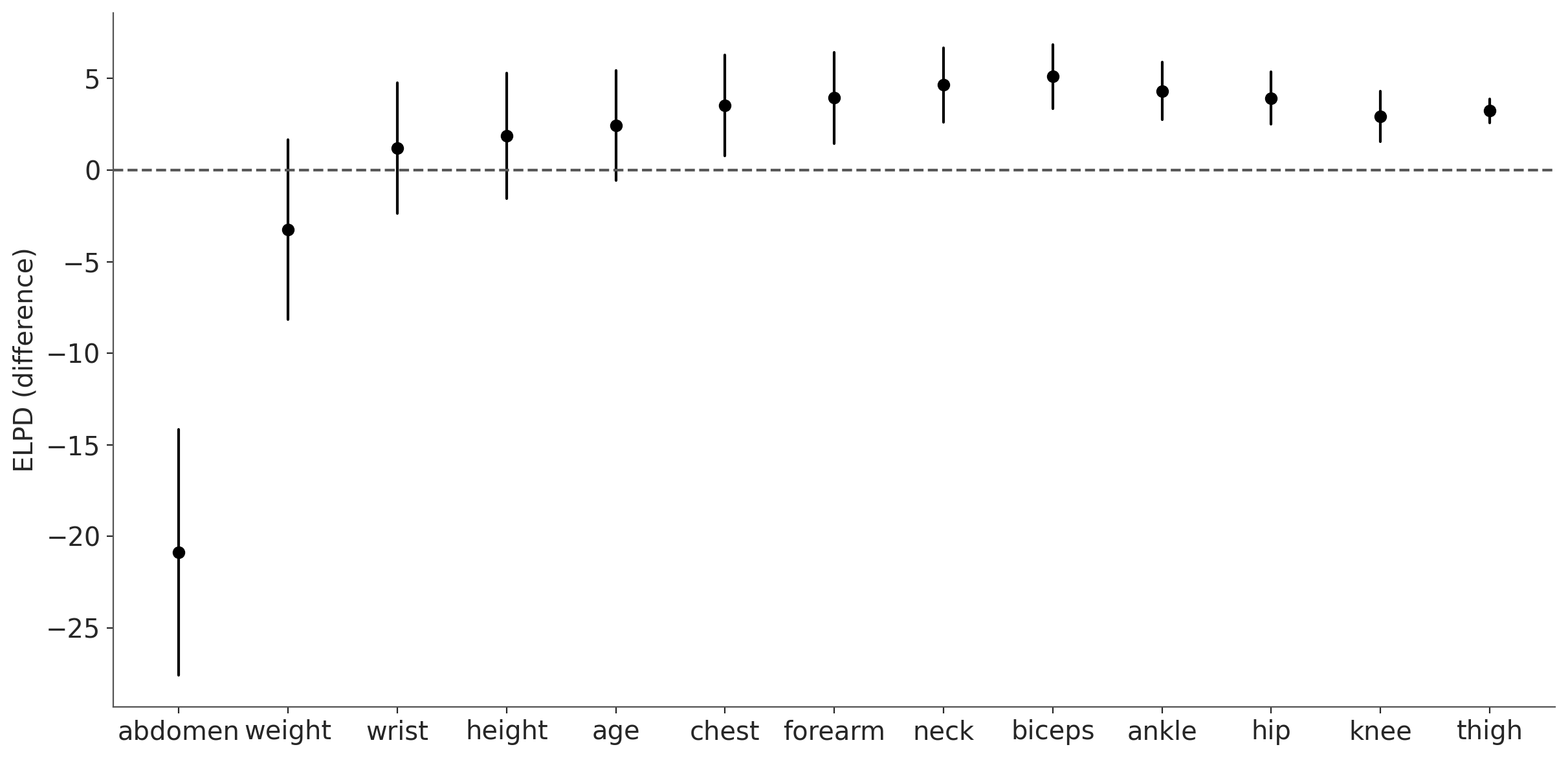
From this plot we can see that the most relevant variable is abdomen, in the sense that if we were forced to pick a single variable, picking abdomen would be the one that would make the predictions most similar to the reference model. But the difference of ELPD between the submodel abdomen and the reference model is large, so we may want to include more variables. If we include two variables abdomen and weight, or maybe tree abdomen, weight and wrist we should get a model that is statistically indistinguishable from the reference model (under the ELPD metric).
The error bars give us an idea of the uncertainty of the ELPD estimate. This is telling us that if we repeat the experiment many times (or computation using a different seed or bootstrap the data), we should expect to get abdomen as the most relevant variable almost 100% of the time. For the second position, weight and wrist are the most likely contenders, though other variables could occasionally take that spot. Similarly, from the previous figure it would not be meaningful to claim that forearm is more relevant than hip.
Automated selection of submodels#
plot_compare provides very useful information in a visual way. However, sometimes we may want a more automated way to select the submodels. This can be done by calling the select method. If we use the select method for our example, we see that the selected submodel is the one with abdomen and weight (plus the intercept, that is always included).
selected_submodel = ppi.select()
selected_submodel
['Intercept', 'abdomen', 'weight']
When using the select method we have two options: mean (the default one) and se. mean selects the smallest submodel with an ELPD that is within 4 units of the reference model. The “se” methods selects the smallest submodel with an ELPD that is within one standard error of the reference model. Both criteria behave similarly. Usually, the mean criterion results in more stable selection, and selects larger and better-performing submodels [6].
As usual statistical methods should help us make decisions, but they should not make decisions for us. When deciding which variables to include in the model we may prefer an order that is slightly different from the one provided by Kulprit, the decision could be based on extra information that is not included in the model. For example, after discussion with domain experts or coworkers, we might determine that weighing patients is too cumbersome and decide to include only abdomen and wrist measurements.
Exploring the projected posterior#
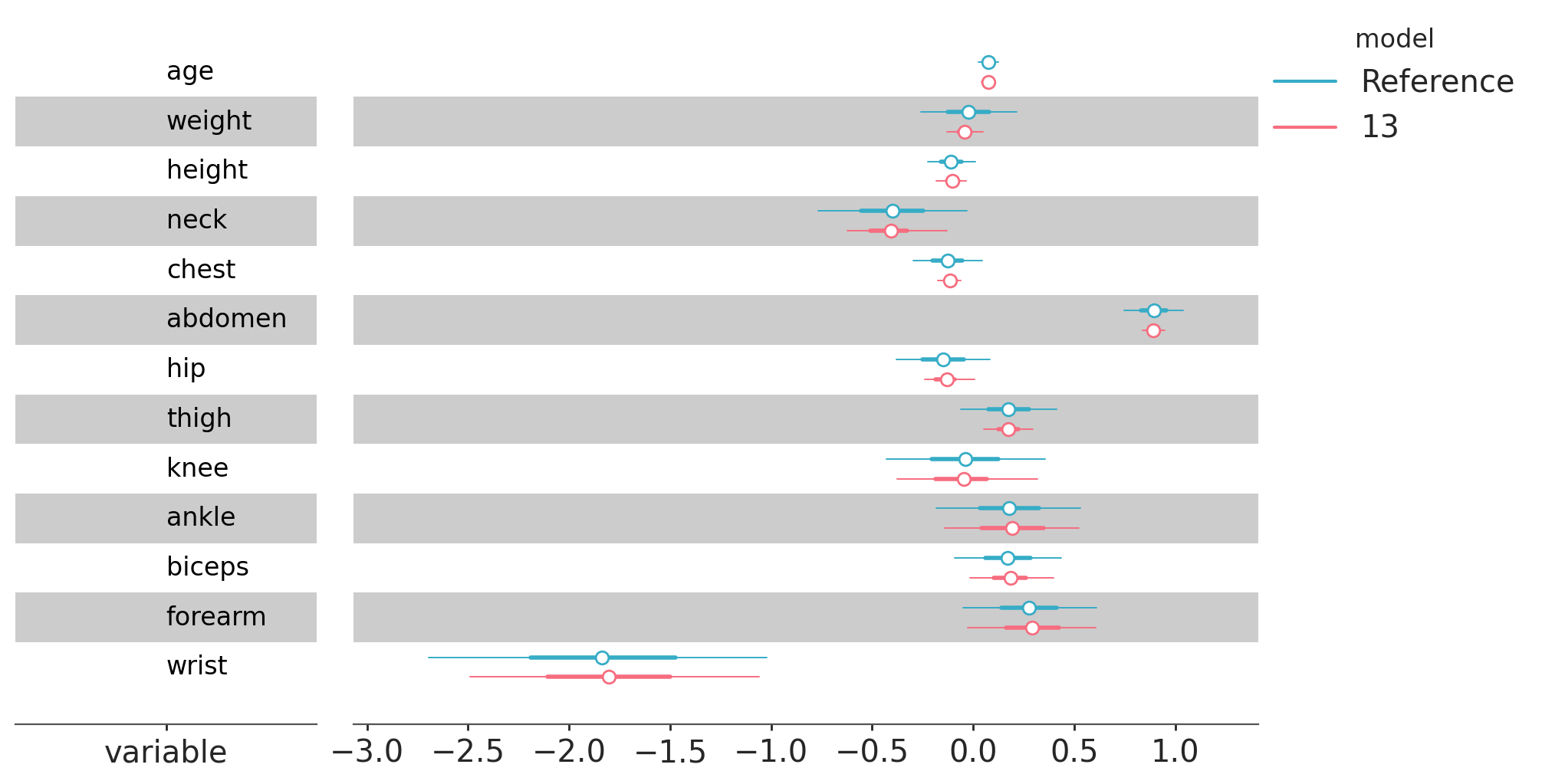
Usually for the purpose of variable selection we do not care about the projections themselves, as they are just an intermediate step to perform variable selection. Nevertheless, it’s possible to use and explore the projected posterior. The plot_forest function allow us to plot the posterior marginals of the submodels (and optionally the reference model too).
In the following figure we can see that the posterior densities of the reference model and the largest submodel (i.e. the reference model projected onto itself) are very similar.
kpt.plot_forest(ppi,
submodels=[13],
include_reference=True,
figure_kwargs={"figsize": (10, 5)},
);
/home/osvaldo/proyectos/00_BM/arviz-devs/arviz-plots/src/arviz_plots/plot_collection.py:56: FutureWarning: In a future version of xarray the default value for join will change from join='outer' to join='exact'. This change will result in the following ValueError: cannot be aligned with join='exact' because index/labels/sizes are not equal along these coordinates (dimensions): 'chain' ('chain',) The recommendation is to set join explicitly for this case.
data = xr.concat(ds_list, dim="model").assign_coords(model=list(data))
/home/osvaldo/proyectos/00_BM/arviz-devs/arviz-plots/src/arviz_plots/plot_collection.py:56: FutureWarning: In a future version of xarray the default value for join will change from join='outer' to join='exact'. This change will result in the following ValueError: cannot be aligned with join='exact' because index/labels/sizes are not equal along these coordinates (dimensions): 'draw' ('draw',) The recommendation is to set join explicitly for this case.
data = xr.concat(ds_list, dim="model").assign_coords(model=list(data))
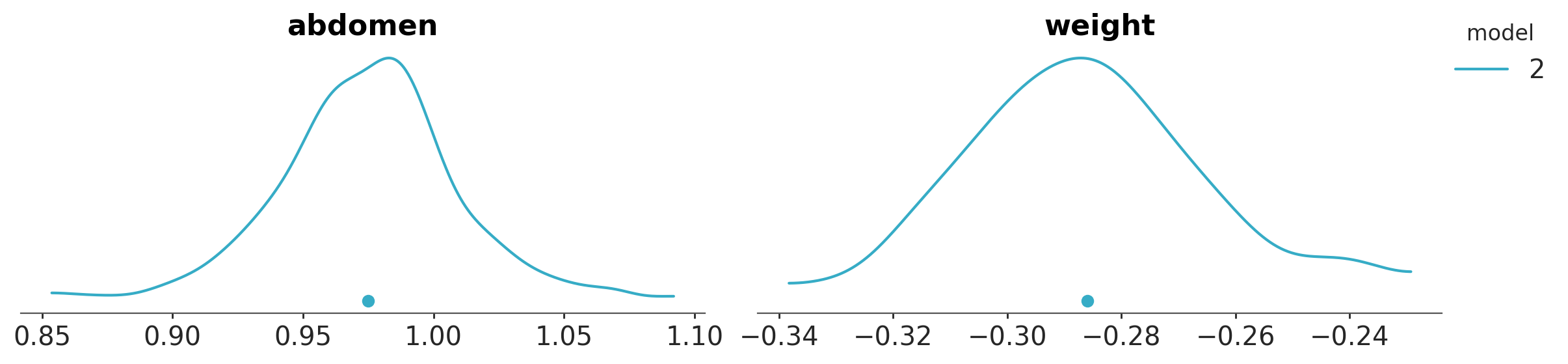
Below we can see the projection for the submodel of size 2, abdomen + weight. This time using the plot_dist function.
kpt.plot_dist(ppi,
submodels=[selected_submodel.size],
);
The plotting functions in Kulprit are thin wrappers around ArviZ’s plotting function with the same names. Kulprit may perform some preproccessing or use different defaults to better suit the purpose of variable selection.
Bikes#
bikes = pd.read_csv("bikes.csv")
We expect rentals to go up in the morning and in the evening, and to go down in the middle of the day and at night. A linear model may have difficulties to handle this kind of non-linear behavior. To better model the effect of the variable hour we could transform it into a set of dummy variables like
bikes = pd.read_csv("bikes.csv")
bikes["hour_sin"] = np.sin(bikes.hour * np.pi / 12)
bikes["hour_cos"] = np.cos(bikes.hour * np.pi / 12)
bikes.drop(columns="hour", inplace=True)
or we could use a more flexible model like splines (that is also a kind of data transformation). Let’s try the latter.
knots = range(1, 22, 5)
priors = {
"alpha": bmb.Prior("Exponential", lam=1)
}
model = bmb.Model("count ~ bs(hour, knots=knots, intercept=True) + " + " + ".join(bikes.columns.drop(["count", "hour"])),
bikes,
family="negativebinomial",
priors=priors)
model.set_alias({"bs(hour, knots=knots, intercept=True)": "bs_hour"})
idata = model.fit()
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [alpha, Intercept, bs_hour, season, month, holiday, weekday, workingday, weather, temperature, humidity, windspeed]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 60 seconds.
Performing the projection#
As previously, mentioned before perfoming variable selection, we need to be sure we trust the reference model. This includes checking MCMC diagnostics and other evaluations like posterior predictive checks. We only skip this step for brevity in these examples.
If you forget to compute the log_likelihood when fitting the model, Kulprit will emit a warning and will compute it for you.
ppi = kpt.ProjectionPredictive(model, idata)
ppi.project()
/home/osvaldo/proyectos/00_BM/bambinos/kulprit/kulprit/projection/arviz_io.py:84: UserWarning: log_likelihood group is missing from idata, it will be computed.
To avoid this message, please compute the log likelihood with
model.compute_log_likelihood(idata)
warnings.warn(
Inspecting the results#
kpt.plot_compare(ppi.compare(min_model_size=1),
visuals={"ticklabels":{"rotation": 70}},
);
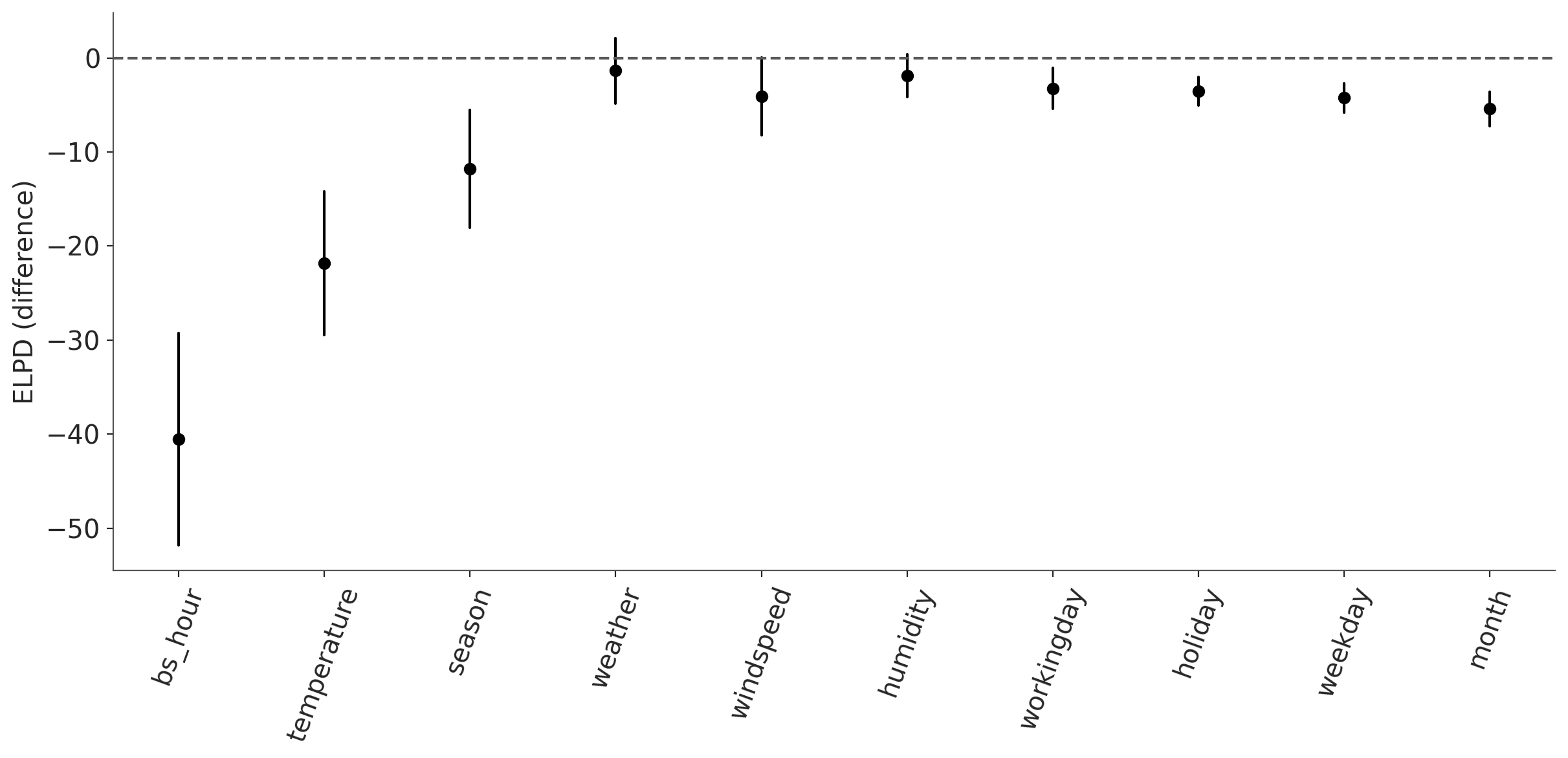
We can see that hour is the most important variable in the model, followed by temperature.
Early stopping#
We may want to stop the projection earlier, specially when we have a lot of variables. We can do this by setting the early_stop argument (defaults to None). The available options are:
The strings
meanorse, their meaning is the same as in theselectmethod.An integer, indicating the maximum model size to project.
ppi = kpt.ProjectionPredictive(model, idata)
ppi.project(early_stop="mean")
kpt.plot_compare(ppi.compare(min_model_size=1));
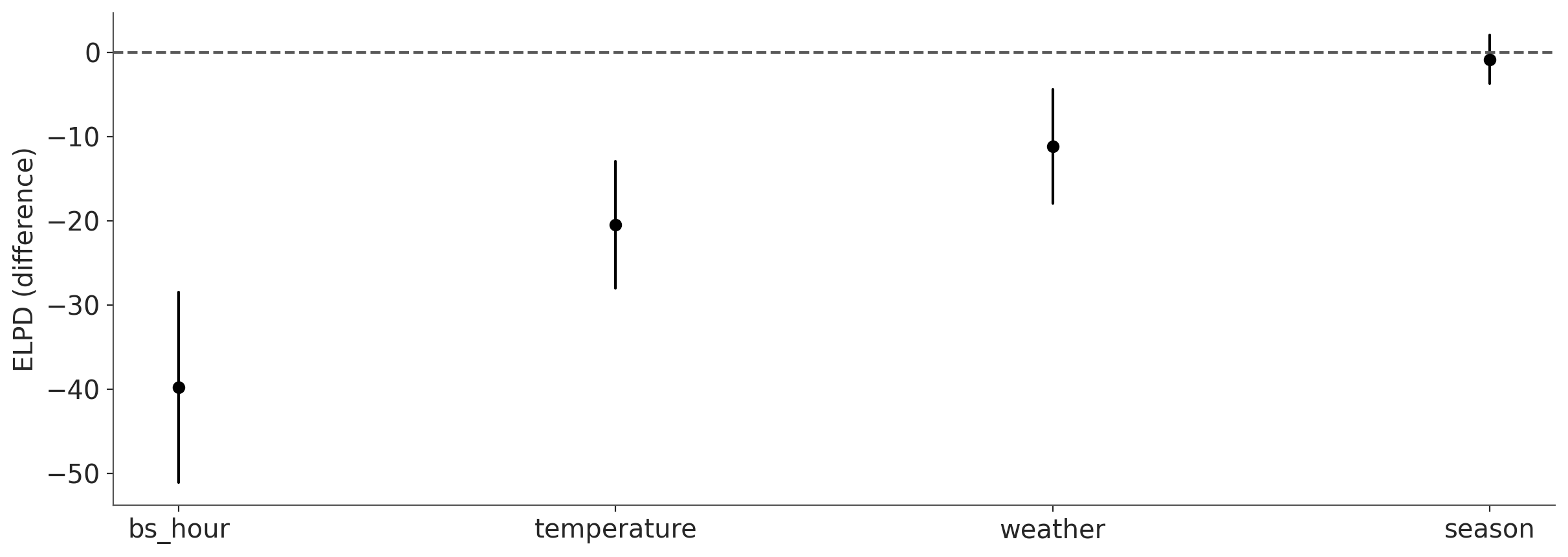
Speeding up the projection#
There are a few options we can use to speed up the projection. It’s important to note that all of them will reduce the accuracy of the results. Still, a faster projection could be useful when we have numerous variables, and we want to perform a preliminary analysis.
To better understand the options we have we need to understand how Kulprit works. You can read the overview for details, but in short, Kulprit performs a search over the terms in the model to find the best submodels for each size, and then it evaluates the performance of each selected submodel. The evaluation step is done by projecting each selected submodel and then computing the ELPD (using PSIS-LOO-CV method) Vehtari et al. [3], Vehtari et al. [4], the result of this evaluation step is what you see when calling compare and plot_compare.
To speed up the search step Kulprit uses a clustering algorithm to group the posterior predictive samples from the reference model. The number of clusters can be controlled using the num_clusters argument. A lower value will speed up the computation, but it will also reduce the accuracy of the search. The default value is 20, but for a quick analysis, a lower value like 10 or even 5 could be acceptable.
During the evaluation step, Kulprit don’t use the clusters, instead it uses a higher number of posterior predictive samples. We can control this using the num_samples argument, which defaults to 400. A lower value like 100 could still provide reasonable results.
Another option is to change the search method. By default Kulprit uses a forward search (method="forward"), but we can also use lasso (method="L1"). This is faster than the default because no projection is done during the search, instead Kulprit performs a lasso search over the terms, and the projection is done only for the selected submodels. The downside is that the search step is less accurate as we loose the benefit of the projection during the search.
Additionally, the argument user_terms can be used to provide the list of terms/submodels that we want to project. This is faster as no search is done. This can be used if we want to use some other method of search not yet implemented in Kulprit (see for example PyMC-BART).
References#
Aki Vehtari and Janne Ojanen. A survey of Bayesian predictive methods for model assessment, selection and comparison. Statistics Surveys, 6(none):142 – 228, 2012. URL: https://doi.org/10.1214/12-SS102, doi:10.1214/12-SS102.
Georg Heinze, Christine Wallisch, and Daniela Dunkler. Variable selection - A review and recommendations for the practicing statistician. Biometrical Journal, 60(3):431–449, 2018. URL: https://onlinelibrary.wiley.com/doi/abs/10.1002/bimj.201700067, doi:10.1002/bimj.201700067.
Aki Vehtari, Andrew Gelman, and Jonah Gabry. Practical Bayesian model evaluation using leave-one-out cross-validation and WAIC. Statistics and Computing, 27(5):1413–1432, 2017. URL: https://doi.org/10.1007/s11222-016-9696-4, doi:10.1007/s11222-016-9696-4.
Aki Vehtari, Daniel Simpson, Andrew Gelman, Yuling Yao, and Jonah Gabry. Pareto smoothed importance sampling. Journal of Machine Learning Research, 25(72):1–58, 2024. URL: http://jmlr.org/papers/v25/19-556.html.
Keith W. Penrose, Arnold G. Nelson, and Arnold Garth Fisher. Generalized body composition prediction equations for men using simple measurement techniques. Medicine and Science in Sports and Exercise, 17:189, 1985. URL: https://api.semanticscholar.org/CorpusID:57308221.
Yann McLatchie, Sölvi Rögnvaldsson, Frank Weber, and Aki Vehtari. Advances in Projection Predictive Inference. Statistical Science, 40(1):128 – 147, 2025. URL: https://doi.org/10.1214/24-STS949, doi:10.1214/24-STS949.